14. Evaluating multiple ideas in parallel during error analysis
你的团队有几个提升猫检测器性能的想法:
- 解决狗识别成猫的问题。
- 解决“大型猫科动物”(狮子、豹等)识别成家猫(宠物)。
- 在模糊图像上提升系统的性能。
- …
你可以同时有效地评估这些想法。我通常建个表格,当我浏览100个误分类开发集图片时填充表格,同时也会一些帮我记住特定样本的评论。用四个开发集样本数据来说明这个过程,你的表格可能是下面这样:
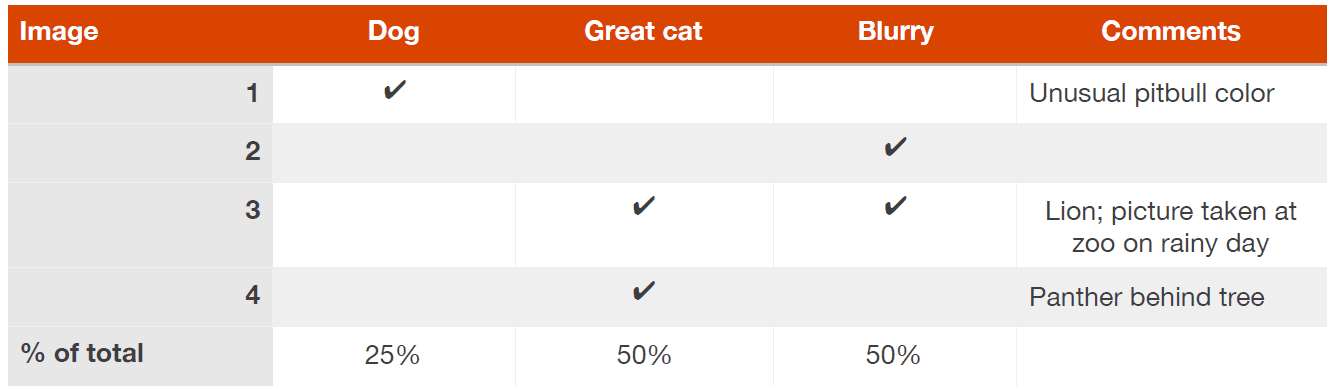
上图第三行在Greate Cat和Blurry 列都被勾选了:一张图可能和多个类别都有关系。这就是为什么最底部的百分比相加不是必须等于100%。
虽然在描述这个过程时候我先定义了类别(Dog,Great Cat,Blurry)然后浏览样本并将它们分类,实际上,一旦你开始浏览这些样本,你可能会受到启发,然后提出新的错误分类类别。比如,在浏览了一些图片后,你发现许多图片上的许多错误来自于Instagram过滤器的预处理。你可以返回到你的表格然后添加“Instagram”列。人为浏览算法出错的样本,然后思考一下人是如何/是否能够得到正确的分类,这通常会给你的新的误差分类和解决方法带来一些启发。
最有帮助的错误类别是你已经有想法如何提高的那个。比如,如果对于“撤销”Instagram过滤器恢复原始图片你有想法的话,那么Instagram类别将是最有用的。但是你不必限制自己在你已经有想法去改进的错误类别。这个过程的目标是建议关于哪方面才是需要被关注的意识。
误差分析是一个迭代过程。你甚至可以在没有任何分类想法时开始。通过查看图片,你可能会得到一些关于错误类别的想法。然后查看并手动分类这些图片,你可能又产生一些其他分类的想法。反悔添加新的类别并重新查看图片,如此迭代。
假设你完成了100个开发集示例的错误分析,得到以下表格:
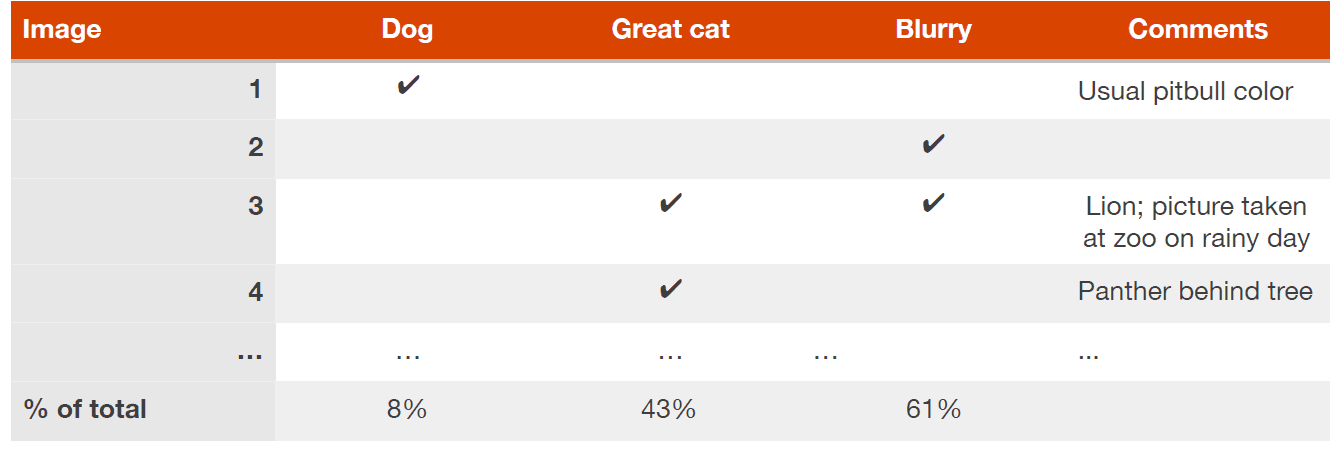
你现在知道了一个解决狗分类错误的方法可以消除最多8%的错误。在Great Cat和Blurry上努力对项目帮助更大。因此,你可能挑选后两者之一继续努力。如果你的团队有足够的人可以同时进行多个方向,你也让一些工程师在Great Cat上努力,另一些工程师在Blurry图像上努力。
误差分析并不会得到一个明确的数学公式来告诉你应该做什么。你必须考虑你希望在不同错误类别上取得多少进展,以及处理每个类别所需要的工作量。